Как скачать, настроить и составить семантическое ядро при помощи программы словоеб?
Привет всем! А вы знаете как пользоваться словоебом? Не подумайте, что я ругаюсь 🙂 Словоеб это замечательная бесплатная программа по составлению семантического ядра.

Программа Словоеб является урезанной версией программы Key Collector. Уж про него то вы точно слышали. В этой статье я подробно расскажу, что это за чудо программа, как пользоваться словоебом, и как составить при помощи него семантическое ядро. Статья большая, поэтому предлагаю воспользоваться содержанием:
Как скачать программу Словоеб;
Как настроить Словоеб;
Как составить семантическое ядро программой Словоеб;
Плюсы и минусы программы Словоеб;
Как скачать программу Словоеб?
Скачать программу словоеб можно с официального сайта разработчиков — [aspan]seom.info[/aspan]. На сайте есть ссылка, кликнув по которой, вы автоматически загрузите архив с программой к себе на компьютер.

После того, как архив успешно загрузиться, нужно запустить программу установки Slovoeb.exe

Важно! Если после запуска программы установщика, выдается ошибка и Словоеб не открывается, скорее всего у вас не установлен автономный установщик Microsoft .NET Framework 4 , а Словоеб работает только с ним. Скачать Microsoft .NET Framework 4 можно здесь. [aspan]http://www.microsoft.com/ru-ru/download/details.aspx?id=17718[/aspan]
После того, как скачаете его, можете смело открывать программу Словоеб и настроив его, приступать к составлению семантического ядра.
Как настроить Словоеб
Итак, вы установили программу Словоеб, теперь нам необходимо ее настроить.
При первом открытии программы можно увидеть такой интерфейс:
Для того, чтобы настроить Словоеб, выбираем в левом верхнем углу значок шестеренки и попадаем в настройки.
Общие.
В этой части настроек задаются общие данные для парсинга запросов. В принципе возле каждого значения стоит знак вопроса с подсказками. Можете просто выставить как показано у меня на скриншоте.
1. Ограничение количества слов в одном запросе;
2. Количество попыток обработки запроса при сбое;
3. Ограничение ожидания ответа сервиса. Не рекомендуется ставить менее 6 000 мс.
4. Режим сбора запросов;
5. Автоматическая фильтрация запросов и удаление ненужных символов;

Yandex Wordstat.
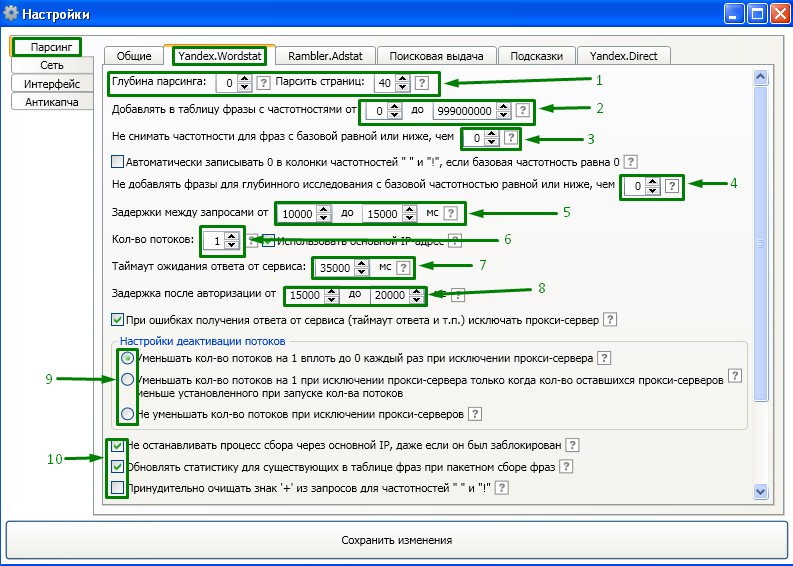
1. Глубина парсинга страниц. Глубину парсинга лучше ставить «0», чтобы система не заблокировала наш IP.Глубину страниц для парсинга я рекомендую ставить не более 40.
2. Здесь можно настроить, фразы с какой частотностью должны быть добавлены в таблицу. Хорошая функция, которая помогает ускорить процесс, если вас интересуют только НЧ, СЧ или Вч запросы.
3. Чтобы ускорить время парсинга, можно изменить значение «Не снимать частотности для фраз с базовой, равной или ниже чем». Я использую значение 30. Можете себе поставить так же.
4. Настройки парсинга как и в предыдущем случае.
5. Задержки между запросами не рекомендуется ставить менее 10 000 мс, чтобы не выскакивала каптча и не блокировался IP.
6. Не ставьте больше одного. Этот параметр предназначен, если вы используете несколько IP адресов!
7. Тайм аут после авторизации и ответа от сервера, опять же не рекомендуется ставить менее, чем указанное по умолчанию.
8. Задержка после авторизации в Яндекс Вордстат. Не рекомендую ставить время меньше чем указанное по умолчанию!
9. Настройка потоков запроса.
10. Отключайте данную опцию, только если используете динамические IP адреса.
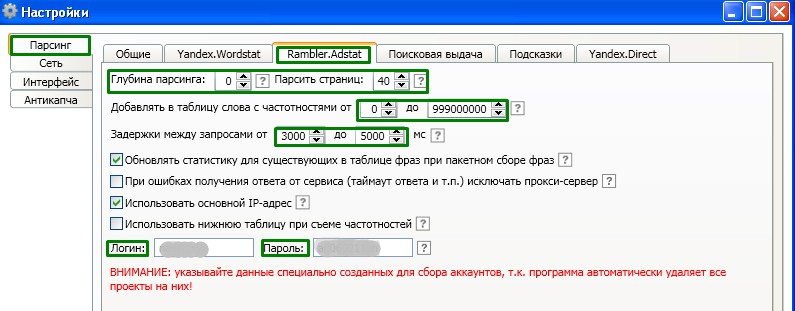
Rambler. Adstat.
Здесь те же настройки, что и для Яндекса.
Выдача.
Настройки поисковой выдачи аналогичны настройкам сбора базовой частотности.

Подсказки.
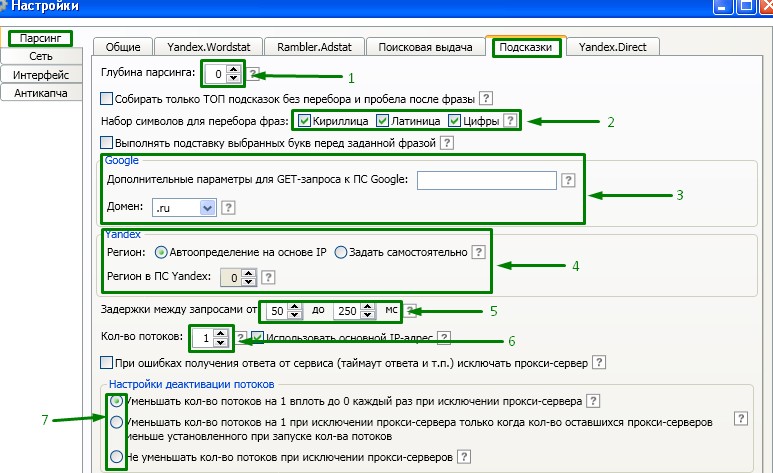
1. Не рекомендуется ставить более чем 0. Этот параметр отвечает за количество обходов списка фраз.
2. Можно задать какие символы стоит учитывать при парсинге, а какие необходимо исключить.
3. Настройки для Гугл по сбору подсказок.
4. Установка региона для поисковой системы Яндекс.
5. Задержка времени запроса.
6. Количество потоков парсинга.
7. Настройки при сбое парсинга.
Yandex. Direct.

В этом разделе нужно авторизоваться в Яндексе, и указать некоторые настройки безопасности.
Экспорт.

После того как вы создадите семантическое ядро в программе Словоеб, вы можете его экспортировать, но несмотря на то, что здесь доступны 2 формата – XLSX и CSV, экспорт доступен только в формате CSV. Первый вариант просто не работает.
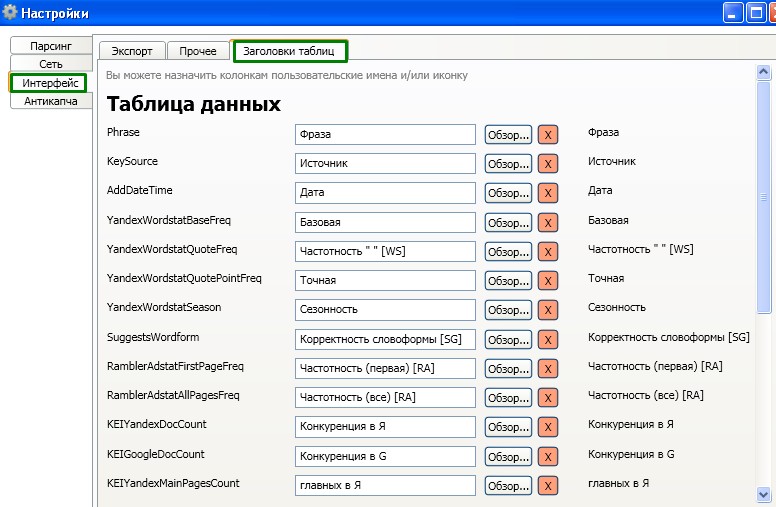
Заголовки таблиц. Очень нужная вещь. Чтобы не засорять таблицу лишними данными и непонятными словами, можно указать свои заголовки в таблицу семантического ядра. Например вместо значения «Количество главных страниц в поисковой системе Яндекс», можно просто указать «морды в Яндекс». И вам будет понятно, и таблица получится аккуратная.
При парсинге ключевых слов, периодически может выскакивать капча. Можно ее вводить вручную, а можно автоматизировать ее ввод. Для этого нужно зарегистрироваться в одном из сервисов автоматического ввода капчи.

Отлично. Словоеб мы настроили, теперь приступим к составлению семантического ядра при помощи программы Словоеб.
Как составить семантическое ядро программой Словоеб
Возьмем какой-нибудь небольшой запрос для примера. Например «отдых в Сочи». Представьте, что у вас есть свой небольшой отель на берегу черного моря 🙂
Для начала нужно создать новый проект:
Назвать его можете как угодно, он нам все равно не пригодится.
Сначала нужно собрать базовую частотность из левой колонки Яндекс Вордстат.

Базовая частотность, это все фразы, в которых будет присутствовать наши слова. Если мы вставим фразу «отдых в Сочи», то в базовой частотности будут и такие фразы как «город сочи», «отдых в Таиланде». То есть все фразы, где присутствуют слова «отдых», «Сочи», «в».
В появившейся таблице вводим наши слова для первичного семантического ядра, и нажимаем – парсить.

Сбор базовой частотности идет довольно быстро. Так как мой запрос имеет большую конкуренцию, я не стал ставить никаких ограничений в настройках, потому что есть вероятность подобрать интересные микрочастотные запросы небольшой конкуренцией.
У меня после парсинга по фразе «отдых в сочи», программа Словоеб нашла 1161 базовый запрос.

Теперь необходимо вручную отсортировать все запросы и удалить лишний мусор. Нам не интересны запросы «отдых в сочи аквалоо отзывы» и «отдых в сочи санаторий дзержинского».
Мы ведь продвигаем свой отель, а не пиарим клиентов и пишем отзывы о других отелях. Поэтому удаляем такие запросы.
После сортировки базовой частотности, у меня осталось всего 535 запросов. Теперь можно собрать поисковые запросы из правой колонки Яндекс Вордстат и собрать статистику Rambler. А затем отсортировать эти запросы аналогичным образом. Правая колонка Яндекс Вордстат позволит подобрать ключевые запросы, которые могут дополнить семантическое ядро.

После того, как вы собрали базовую частотность, нужно собрать точную частотность, чтобы отсеять все запросы пустышки, которые не принесут нам трафика. Для этого в меню программы словоеба выбираем раздел «Сбор частотностей» и начинаем собирать точную частотность.
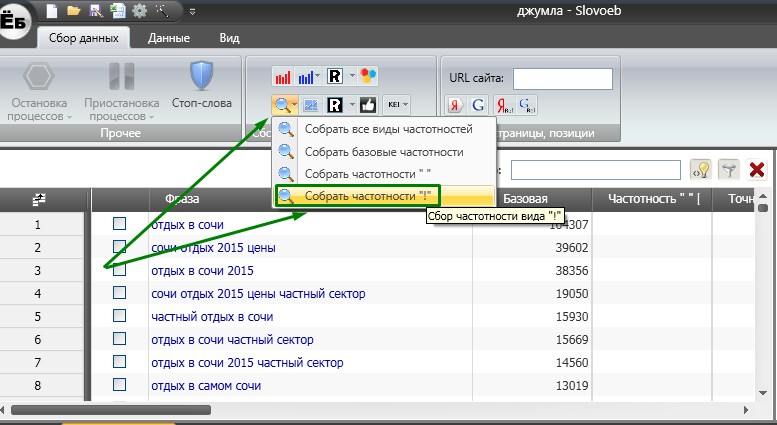
Этот процесс длится немного дольше. Мои 535 запросов, программа Словоеб обрабатывала часа полтора.
Отлично у нас есть базовая и точная частотность. Теперь нужно удалить из таблицы все фразы с точной частотностью менее 5 и фразы с большой разницей между базовой и точной частотностью. Например, фраза «отдых в сочи у самого моря» имеет большую разницу и мы ее смело удаляем.
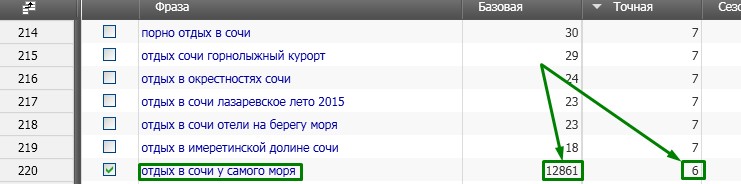
Теперь у нас осталось всего 263 запроса, но это еще не все. Теперь нужно проверить конкуренцию по каждому запросу и снова удалить все лишнее. Так как программа Словоеб имеет ограничения в отличие от KeiCollector, я рассчитываю конкуренцию следующим образом.
Выбираю в меню «рассчитать все данные KEI», и жду, когда программа высчитает количество главных страниц по заданному запросу, количество страниц в выдаче и количество вхождений в title страниц, чтобы уже потом на основе этих данных еще раз проанализировать все данные.
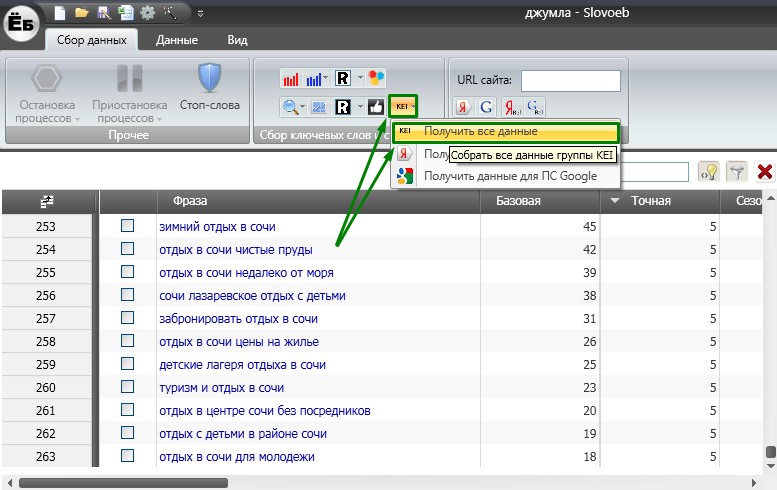
Высчитывание KEI довольно долгий процесс, у меня он занял около 3 часов.
Теперь вы можете проанализировать частотность, если это имеет для вас значение. Если же нет, то давайте удалим все фразы, для которых количество главных страниц в ТОПе более 7. Можете их и оставить, но помните, что в ТОПе только 10 мест, а если при этом присутствуют все главные страницы, то у нас очень маленький шанс их обойти. Так же можно удалить фразы, для которых показано большое количество сайтов в выдаче с ключевой фразой в title. Но это уже на ваше усмотрение.
После удаления высококонкурентных запросов, экспортируем составленное в программе Словоеб семантическое ядро сайта, и окончательно обработаем его уже в формате Exel на компьютере.
Как я уже говорил выше, экспортировать можно только в формате CSV, а затем вручную можно перенести в Exel.
У меня в итоге получилось 264 запроса в семантическом ядре:

Семантическое ядро мы составили, теперь нужно разгруппировать все запросы по статьям и рубрикам, то есть сделать кластеризацию запросов. Это можно сделать как вручную, так и при помощи специального софта или сервисов. Но об этом я расскажу уже в другой статье.
Плюсы и минусы программы Словоеб.
Конечно, как и у любой программы, у словоеба есть свои плюсы и минусы. К плюсам можно отнести – бесплатность программы, автоматизация работы, удобный интерфейс.
К минусам – отсутствие возможности сбора статистики с Google и отсутствие обновлений.
Подписывайтесь на обновления блога, чтобы не пропустить!

Крутая штука, жаль не воспользовался в свое время. Где ты раньше был со своим постом?
Вот и я думаю, чего это я раньше не задумывался о семантическом ядре для блога 🙂 Столько времени было бы сэкономлено, да и посещаемость была бы совсем на другом уровне.
Спасибо большое:) Завтра в офисе буду , по вашей статье пройдусь — сделаю всё как написано 🙂 Только сегодня о ядре задумывался и вот 🙂 Буду читать ваш блог! Спасибо !
P.S. — жду статьи про «кластеризацию» )
Скоро появится 🙂
давно присматриваюсь к этой программе, но всё руки не доходят.
Вопрос, а в платной версии есть сбор статистики с гугла?
У словоеба нет платной версии, только бесплатная. Есть аналог от тех же разработчиков — KeyCollecor. У него возможностей гораздо больше, в том числе и статистика с Google.
Стыдно признаться, моему блогу уже несколько лет, а нормальное семантическое ядро до сих пор не составлено. И ведь знаю прекрасно, что нужно это исправить, да все руки не доходят. Спасибо за ваш пост, он для меня как волшебный пендель))
Пожалуйста, Настя! Рад что оказался полезен 🙂
Мне брат посоветовал такую программку для подбора слов, при создании и разработке сайта мы использовали её! Спасибо за полезную информацию размещённую на вашем сайте!
Key Collector мне недавно одна сеошница посоветовала, хотя упоминала и Словоеб. Думала, что это — одно и то же, но нет. Сейчас попробую скачать и установить.
Я составляла семантитческое ядро с самого начала, но судя по посещалке что-то сделала не так. Признаться, не могу уловить сути организации ядра. Особенно для блога о еде. Каждый продукт — ключевик,не говоря о теме диет,похудения, ЗОЖ. Буду изучать эту программу.
Для блога действительно не так просто составить СЯ, особенно если блог охватывает обширную тему. Я думаю в таких случаях как вариант можно делать упор на большое количество статей НЧ и НК запросов.
А мне больше нравился кей коллектор, слово… не пользовался.
Юр, разумеется 🙂 Это по сути две программы одного разработчика, только Кейколлектор лучше и функциональнее в несколько раз.
Андрей, привет! А что значат цифры в колонке «конкуренция в яндекс» — 200000 или 40000 и т.д.?
Это количество страниц, которое находится в индексе Яндекса по точному запросу, чтобы примерно можно было ориентироваться на конкуренцию запроса.
В КейКоллекторе с этим делом намного лучше, там высчитывается KEI (оценка ключевого запроса) по специальной формуле.
Скажу честно, я умудрялся долгое время работать с Словоебом, собирая семантику для сайтов и для контекстной рекламы. Но потом как-то понял, надо шагать дальше, и стал покупать софт, первым в коллекции стал Key Collector. Но для личного использования и Словоеб является серьезным подспорьем.
Я тоже пока пользуюсь Словоебом, в ближайшее время буду брать лицензию на Key Collector.
Я тоже из тех, кто все время думает об этом семантическом ядре, но все никак ним не займется. Пока просто для каждой статьи подбираю ключевые слова, учитывая частоту и конкурентность. Надеюсь, еще не поздно сделать все по правилам и составить уже наконец-то это ядро..
Никогда не поздно, но чем быстрее, тем лучше 🙂
Программа, несомненно, хорошая, но заточена исключительно под винду. Увидеть бы версию под Мак или Линукс очень хочется. А так пока только скриншоты посмотрел, помечтал и ушел))
Раньше пользовался такой. А сейчас прочитал и думаю, что нужно ещё раз пройтись ей по сайту. Поменяю думаю не мало!
Начинал тоже со словоеба, но в дальнейшем перешел на его старшего брата кейколлектор. Считаю что любой вебмастер должен иметь его в своем арсенале. Цена не такая уж и большая.
Да, Кейколлектор это вещь 🙂
Здравствуй, Андрей. Вот нужно ядро составить как раз. Сейчас буду делать.
Андрей, меня на составление всего ядра за раз не хватило. Только левую колонку отфильтровал. Сохранил пока так. А вообще лично мне больше и не надо функционала. Да, удобно после составления ядра будет делать разделы сайта.
Привет, Егор. Левая колонка дает лишь базовую частотность. Этого недостаточно, так как данные далеко не точные. Например, если для фразы «Как создать сайт на WordPress» базовая частотность составляет 966 запросов. Это значит что показана вся частотность, где упоминаются слова создать, сайт, WordPress. Если же посмотреть эту фразу по точной частотности, то получиться гораздо меньше.
Я понимаю, просто пока отложил файл. Сейчас продолжу 🙂
Ясно 🙂
Я тоже работаю с Кейколлектором, ведь у него больше возможностей.
«Букварикс» недавно мне предложили. Автор сказал, что пока программа бесплатная и сбор ядра проходит на автомате. Поверила. Скачала программу весом в 15 гигов, а распаковать не смогла. Теперь я доверяю только кейколлектору и базе Пастухова.
Я Букварисом не пользовался, поэтому ничего не могу сказать.
А вы пользуетесь базой Пастухова?
Сегодня скачал словоеб. Буду разбираться, не до конца понял все, но думаю научусь на своих же ошибках.
Удачи! Будут вопросы,обращайтесь.
Скажите, пожалуйста. А как быть в таком случае. При определении конкурентности по одному ключу по разным поисковым системам Я и Г показывает разный результат. Например, по отношеню к Яндексу Главная 0, Запросов в тайтле 8, а в гугле наоборот Главных 8, а Запросов 0. Как быть в этом случае, оставлять такой запрос или убирать?
Ну алгоритмы у этих ПС разные,поэтому и разница такая. В любом случае 8 точных вхождений это многовато, я бы такой запрос в счет не брал. Ну или как вариант можете проверять конкуренцию в Mutagen, он показывает точную конкуренцию. В случае же с программой, среди этих 8 запросов вполне могут оказаться обычные дорвеи, которые вскоре вылетят из поиска.
Андрей, здравствуйте, скачала словоёб, а там всё по-английски, не подскажете, как эту прогу к русскому языку приобщить? Заранее спасибо.
Здравствуйте, Татьяна. Странно, это полностью русскоязычная программа. А вы скачивали с официального сайта? Вот ссылка где можно скачать — http://seom.info/tools/
Андрей, спасибо за ответ! Вы первый, кто внятно и понятно ответил на мой вопрос. Обращалась за помощью ко многим известным «гуру», но кроме напыщенного ответа, процеженного сквозь зубы я никакой помощи от них не получила. Теперь хоть понятно, что в Словоебе не стоит проверять запросы на конкурентность. Скажите, пожалуйста, вот некоторые советуют проверять конкурентность в программе СЕО Пульт. Загружаешь слова и смотришь на стоимость продвижения, если она составляет от 5-10 руб., то такой запрос можно брать. Как вы посоветуете, лучше пользоваться Мутагеном или СЕО Пульт? Не могу прийти ни к какому единому знаменателю по анализу конкурентности. Какой из способов является наиболее точным? Или все они условны? Помогите пожалуйста разобраться.
Я рад,что оказался полезен.
СЕО Пульт он лишь показывает стоимость клика. Для коммерческих запросов это можно брать в счет при оценке конкурентности, но в случае с информационными запросами этот метод работать не будет.
В Mutagen рассчет конкурентности идет от многих факторов и никто не знает этой формулы. Но по опыту могу сказать что он отлично справляется со своей задачей.
Лучше всего пользоваться программой key kollector (программа платная). В ней можно собирать данные из Яндекс Вордстат, Google. Adwords, поисковых подсказок, похожих поисковых запросов. После парсинга можно проверить конкуренцию в Mutagen, привязав свой аккаунт к программе и в том же Сео Пульте.
Андрей, а как объяснить вот такой результат? Только что проверила запрос в Мутагене и показало конкуренцию 25, а вот в Словоебе Количество Главных и Запросов в Заголовке по 0. И как бы получается что запрос низкоконкурентный? Я что-то уже совсем запуталась. Или не стоит все-таки проверять конкуренцию по Словоебу, а пользоваться только данными Мутагена?
Словоеб показывает только наличие точного вхождения запроса в title страницы и количество главных. Но для рассчета конкурентности запроса это маловато. Мутаген берет гораздо больше факторов, что это за факторы не знает никто. Многие пытались воссоздать формулу рассчета конкурентности (KEI), которая бы более менее походила на результаты Мутагена, но пока насколько я знаю это никому не удалось.
Я бы вам посоветовал следующее. При помощи программы Словоеб собирайте запросы, затем удалите ключи, которые показывают количество Главных и Запросов в Заголовке более 2. Оставшиеся запросы можно прогнать через Мутаген для оценки конкурентности по оставшимся фразам.
У меня сайт по продаже физических партнерских товаров. Запросы и коммерческие, «Купить» и некоммерческие «Отзывы». На какой сервис мне лучше ориентироваться для оценки конкурентности? Сайт очень молодой.
Лучше ориентироваться на Mutagen.
Сайт ваш понравился. В плане монетизации очень перспективный.
Еще скажите пожалуйста, если пользоваться Кей коллектором, то надо ли еще будет дополнительно также использовать Мутаген? Или анализа конкурентности одного Кей будет вполне достаточно. Т.е. проанализаровал, получил результаты по конкурентности, отсортировал НК и можно писать под них статью? Прошу прощение, что пишу не в одном сообщении, а сумбурно. Просто по мере размышлений и анализа вопросы возникают хаотично.
Да, Mutagen нужно будет использовать дополнительно. KEI не даст оценки конкурентности, он лишь покажет качество ключевой фразы, то есть стоит ли на этот запрос тратить свои усилия. Даже если KEI будет отличным, в Mutagen конкуренция может превысить 25.
Господи, Андрей! Дай вам бог здоровья и всего самого лучшего! Я даже не ожидала, что вы так подробно и, самое главное, понятно ответите на мои вопросы! Вы не представляете сколько я билась над этим. К каким только «светилам» не обращалась! Огромное вам спасибо! Теперь я ваша подписчица и постоянный читатель, так как только на вашем блоге нашла действительно полезную и ПОНЯТНУЮ для новичка информацию. Ваш блог посоветовала всем своим знакомым))) Очень вам благодарна за объяснения. Теперь понятна сама процедура и последовательность анализа.
При анализе слов у меня как раз и получилась такая ситуация, как вы описали — KEI отличный, а Мутаген 25. Теперь четко видно, что из списка в 93 слова НК остаются только 7, а по данным Словоеба получалось, что почти все слова можно брать, так как почти по всем показало 0.
Еще такой вопрос. Как вы посоветуете, покупать Кейколлектор или все-таки достаточно Словоеба? Или же Кей показывает более точные данные?
Вам спасибо, Татьяна, за такие теплые слова!
Я бы на вашем месте купил Кейколлектор. Словоеб всего лишь очень урезанная версия Кейколлектора.
Андрей, большое спасибо! Значит в ближайшее время приобрету Кей, поскольку работы с ключами предстоит много.
Не авторизируеться?
Добрый день! У меня программа Словоеб не работает, точнее не парсит. Выдает ошибку, не могу понять, в чем дело. Подскажите, пожалуйста.
Здравствуйте Андрей! Скажите, правильно я понимаю, что если у фраз точная частотность менее 5, их стоит все удалить, не смотря на общую частотность в несколько тысяч? Просто не совсем понимаю, что такое «точная частотность» и почему получается такая большая разница.
Здравствуйте, Катя. Смотрите, точная частотность это частотность определенной фразы без каких либо изменений, склонений и т. д., например: «приготовить борщ».
Базовая (общая) частотность, это частотность той же фразы в разных вариантах, например:
Как видите, вариантов базовой частотности может быть очень много, Поэтому основной акцент делается на точную частотность.
Я рекомендую удалять фразу если точная частотность меньше 5, но это касается информационных запросов. В случае с коммерческими, этот параметр можно понизить, если позволяет конкуренция ключевой фразы.
Добрый день! Подскажите, а почему у меня пишет не удалось авторизоваться в сервисе Я.Директ, аккаунт вычеркнут из списка, что можно сделать в таком случае?
Возможно аккаунт был заблокирован. Новый создавать не пробовали?
Нет еще не пробовала, попробую, просто посмотрела кто-то сказал обязательно новый зарегистрировать, иначе старый могут заблокировать, так я новый и зарегистрировала, только внесла данные в программу и получается заблокировали. Могут, получается, снова заблокировать?
Если слишком много запросов, то и по IP могут заблокировать.
Андрей, привет! Надеюсь вы не против, если я буду обращаться к вам на «ты»?))) Я опять к тебе с вопросом))). Помоги пожалуйста разобраться. При выборе ключей для своей статьи я всегда анализирую статьи конкурентов, смотрю, какие они ключи использовали в своей статье. И вот у одного из них обнаружила такую штуку. В статье присутствуют ключи, по которым практически нет показов. Например, мазь от варикоза N – 10 показов в месяц и это без учета оператора «!».
Это можно было бы объяснить, если бы статья была старая, скажем, написанная полгода назад. Тут все логично: в начале запрос был 200 потом постепенно спрос упал и стал 10 показов. Но статья новая. Обвинить конкурента в СЕО неграмотности я не могу, поскольку знаю его образованность в этом вопросе и его педантичность по поводу СЕО.
Я логически не могу понять, зачем на сайте публиковать такие статьи? Ведь по таким запросам вообще никто не придет на сайт, не говоря уже о покупке товара. Может быть это какой-то прием, о котором я просто не знаю или новые технологии в СЕО, так сказать?
Когда я выбираю офферы, то сразу прогоняю их на Вордстате и смотрю, есть ли достаточное количество запросов по ним. И далеко не по всем офферам они есть. Но у конкурента на сайте их просто куча, именно таких офферов, по которым очень мало показов. Зачем же такие обзоры публиковать на сайте? Разве они принесут трафик и покупателей? Я что-то вообще ничего не понимаю. Не могу логически сама себе объяснить, что это значит? И зачем так делать? Возможно, я просто не знаю о какой-то хитрости публикации таких обзоров?
Я уже думала так. Наверно он пишет статью под те ключи, которые в данный момент есть, па потом, когда оффер наберет обороты и показы, станет более популярным, просто добавляет в уже опубликованную статью недостающие ключи, по которым уже есть показы? Например, в начале ключ «купить мазь» показывал 10, а со временем стал показывать 200 и его вставили в статью.
Может быть, ты подскажешь, что сие может означать? Как-то такие действия не вписываются в общие правила СЕО. К сожалению, у самого хозяина сайта спросить не могу, хоть это и мой хороший знакомый. Он уже давно не выходит на связь. Он когда консультировал по партнеркам, то сам меня учил, как ключи надо тщательно подбирать и всякое такое. Всегда к этому вопросу очень трепетно подходил, показывал как их выбирать, как отсеивать. А теперь вот я не пойму, как же он сам-то такие ключи и статьи с ними пропускает на свой сайт?
Может и правда, это какой-то новый метод оптимизации и повышения трафика, о котором я еще не знаю?))
Привет, конечно не против 🙂
В данном случае скорее всего берутся товары, и соответственно ключи, которые только начинают набирать популярность, и предположительно будут иметь успех в будущем. Все дело в том, что Вордстат опаздывает, то есть показывает статистику за прошлый месяц. А чем раньше опубликовать статью об определенном товаре, тем больше шансов выйти в ТОП по нужным ключам и произвести продаж. На эту тему могу посоветовать изучить вот эту статью: http://partnerkin.com/blog/stati/poiskovoe_prodvizhenie_sajtov_pod_cpa
Андрей, спасибо огромное за ответ! Т.е. я правильно поняла, например, есть новый оффер. По нему в данный момент времени есть только три ключа с частотностью например 5, 10, 12. Смотрим в Историю запросов — оффер растущий, набирающий популярность. Значит я вписываю в статью все эти ключи, не боясь, что в данный момент по ним мало показов? А можно, например, сделать так? По офферу, например, имеются ключи купить товар-5 показов, цена товара-10, инструкция товара-12. Я их вписываю в статью. Но одновременно с ними я вписываю ключ «состав товара», «товар отзывы», например. Т.е. вписываю те ключи, которые возможно в будущем будут задавать люди. Ну логически прикинуть, какие еще запросы могут быть по данному товару и их заранее вписать в статью даже если в данный момент времени их нет в статистике. Т.е. на будущее так сказать. Ведь можно же прикинуть, какие запросы могут в будущем задавать посетители, что их будет интересовать. Таким образом, как бы заранее добавляя ключи, по которым ыв дальнейшем будут показы. Конечно спрогнозировать сложно, но у всех товаров практически одни и те же запросы: купить, цена, отзывы, состав и т.д.
Да, вы правильно поняли. Именно так все и делается.
Еще такой вопрос. А откуда же тогда возьмется трафик, если большинство статей будут с вот такими запросами? Я что-то совсем запуталась)))
В данном случае не обязательно получать много трафика.
За счёт маленькой конкуренции даже несколько сотен целевых посетителей способны приносить десятки тысяч в месяц.
Андрей подскажите пожалуйста. Скачал, все настроил а при поиске он тут же выдает — не удалось авторизоваться в сервисе Yandex.Direct [для Yandex.Wordstat] (ошибка 3). Аккаунт вычеркнут из списка.
И все ничего не работает. как это исправить?
Александр, попробуйте зарегистрировать новый аккаунт в Яндекс и парсить с новыми данными.
Андрей, привет. Пользуюсь программой в течении года наверное. Случился казус. Гугл блокирует ай-пи и соответственно KEI не выдает. Не в курсе что делать?
Привет. Это из-за большого количества запросов. Если используется динамический адрес, то может помочь перезагрузка модема. Если IP, то ничего не поделаешь, остается очистить кэш и ждать когда гугл помилует. Обычно через несколько дней блокировка снимается.
В том-то и дело что не снимается на протяжении месяца уже. Прогоняет запросов 100 и всё. Не включал программу дней 15 чтоб посмотреть. Ничего не изменилось. Перезагрузка модема ничего не дает
Можно попробовать увеличить время запроса. Если прогоняет 100 запросов, значит идёт блокировка из-за частого обращения к поисковику. Времени на парсинг будет уходить больше, зато блокировки не будет. Какое стоит время между запросами в настройках?
Яндекс Вордстат стоит задержки между запросами от 5000 до 15000.
поисковая выдача от 3000 до 5000.
посмотрел сегодня даже не 100, от 40 до 50 запросов.
Я бы увеличил время. Например для Кей Коллектора рекомендуют ставить задержку от 20 000 до 25 000 мс — http://www.key-collector.ru/preferences.php#googleadwords_timeouts
Андрей, еще вопрос не в тему статьи. Реклама на блоге есть? Цены на странице актуальные?
Да, реклама есть и цены актуальные.
Здравствуйте, пользуюсь программой не из СНГ и на каждый запрос к Yandex.Wordstat в прямом смысле выскакивает капча, я подключил ruCaptcha, но по времени долго получается, на каждое ключевое слово требуется решение капчи. Есть какие-нибудь варианты, чтобы исправить это дело?
Уведомите на почту, если последует ответ, заранее спасибо!
С Новым годом 🙂
Здравствуйте. Можно купить прокси и парсить в несколько потоков.
Добрый день, а если более 2000 фраз не выводит? что делать?
Здравствуйте. Смотря что у вас за тематика. Бывают настолько узкие ниши, что и тысяча фраз это роскошь. Если же у вас тематика не такая узконишевая, то пробуйте расширять за счет поисковых подсказок, похожих поисковых запросов. Как вариант, можно взять запросы с Букварикс, о нем я писал здесь.
я имею ввиду сама программа не выводит более 2000 фраз, хотя по частотности заканчивается на 279.
Здравствуйте, Андрей. Коротко о себе: Работающая пенсионерка. Пытаюсь научится зарабатывать в интернете, в частности меня интересует заработок на партнёрских программах. По этой теме создала группу в ВК. Мой вопрос: Нужно ли делать SEO оптимизацию в этом случае? Конечно я пытаюсь её делать, но надо сказать,что делать трудно. Тема тяжела для понимания. Я буду рада Вашему ответу.
Здравствуйте, Татьяна. Что касается SEO отимизации группы ВК, то вся ее оптимизация сводится к оптимизированному названию и описанию группы. Ну и конечно не стоит забывать о качественном наполнении и дизайне.